老黄放大招 Ampere GPU正式来袭
 技宅空格
技宅空格原本 Ampere(安培)架构 GPU 应该在两个月之前推出的,但因为疫情的原因,NVIDIA 也不得不推迟 GTC 的时间,而且这一场原定在线下召开的会议也不得不从线下改到了线上。
这使得 NVIDIA 原本准备要在 GTC 中推出的 Ampere 架构 GPU 跟着一并推迟了大约两个月的时间,很多 PC 硬件爱好者对这个新显卡架构是充满期待的,尤其是在当下 NVIDIA 率先提出不少新技术的情况下,很多朋友都很希望这一代新架构的 GPU 能够给图形计算带来新一轮的变革。
以往,NVIDIA 每一轮对架构的更新基本上都会伴随着一波技术升级,对于我们这些普通的消费级用户来说,最明显的体现就是游戏画面的提升,每一轮硬件迭代都会带来很可观的游戏画面质量的提升。
当然,更高的计算力也会给玩家们的游戏体验带来更高的流畅度,更新的硬件往往都能更好地应付前一代 3A 级大作对硬件的需求,以前不能跑到很流畅的游戏在升级硬件后能很流畅地跑起来,这也是促进很多玩家持续更新硬件的一个原因。
作为 NVIDIA 旗下的最新一代架构,作为普通消费者,我们普遍关心的方向有两个,第一个是它相较于现有的 Turing 架构能带来多少的、在游戏中可以明显表现出来的实质性性能提升,第二个是 NVIDIA 在 Turing 架构里加入的 RT Core、Tensor Core 在这一代架构里会以什么样的形势发展。
目前 NVIDIA 虽然还没有推出基于 Ampere 架构的游戏卡,只是按照惯例推出了一张专业级的计算卡,但是通过对比中这一代计算卡和上一代的 V100,我们也可以大致看出这一代架构的提升之处。需要注意的是,上一代 NVIDIA 的计算卡 V100 并不是 Turing 架构,而是 Volta 架构,它和 Turing 架构之间还是有一定不同的。

作为新一代架构,NVIDIA 和其他芯片厂商类似,都在这一代产品上跟进了 7nm 制程工艺,这允许他们堆叠更多的晶体管、更多的流处理器,但是芯片的发热和功耗并不会有很多的提升,仍然可以控制在一个合理的范围内。
相较于上一代的顶级计算卡,A100 增加了大约 1800 个流处理器,这使得它的性能得到了更进一步的增强,单单一张 A100,其单精度浮点数的性能已经逼近 20Tflops,对于 GPU 来说,这个算力非常恐怖。作为对比,尚未上市的 Xbox Series X 性能是 12Tflops,而 NVIDIA 自家的 RTX 2080 Ti 能够达到 14Tflops。
如果按百分比算,那么对比 Xbox Series X,A100 的提升幅度是 60%,对比 RTX 2080 Ti,提升幅度也接近 43%。即使是对比 NVIDIA 自家上一代顶级的计算卡 —— V100,它的提升幅度也能达到接近 24%。单纯看 Ampere 架构在单精度浮点、双精度浮点上的能力提升,新一代游戏卡的提升或许是非常可观的,因为它们也很可能会像 A100 一样进一步提升流处理器核心的数量,进而在浮点运算性能上得到一个提升。
至于 A100 的另一大提升 —— 显存,除非 NVIDIA 决定在游戏卡上用 HBM2(不过笔者个人认为可能性不大),否则 A100 在这方面的提升很可能是不会出现在游戏卡上的,不具有什么参考性。
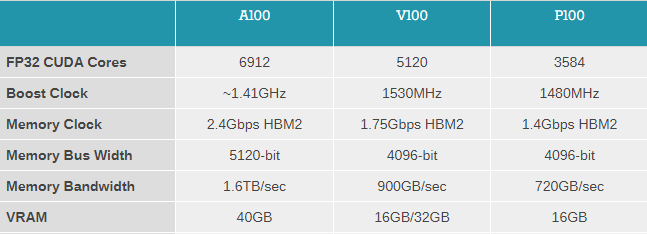
在 A100 上,NVIDIA 把现存的频率、带宽都做了非常大的提升,其中显存带宽达到了恐怖的 1.6TB/s,这是一个相当惊人的带宽大小,除此之外,显存本身 2.4Gbps 的频率相较于 V100 也是有了突飞猛进的提升。
很显然的是,NVIDIA 必然不会在游戏卡上做这样的升级,否则这会大幅度提升游戏卡的成本,也会给游戏卡的 VRAM 散热带来不小的压力。所以 A100 在显存方面的提升,在笔者看来可参考的意义不是很大。
关于 Ampere 架构,NVIDIA 并没有把重心放在 RT Core 上,这可能有两个原因,第一是他们针对游戏卡留了一手,这方面的东西可能要到他们正式发布新一代游戏卡的时候才会说,第二是 Ampere 可能本身并没有那么注重 RT,反而它会更注重计算一些。
为什么这么说呢?因为 NVIDIA 自己在他们的官方博客上就重点提到了,Ampere 架构的两个重要亮点都和这一代 GPU 的 AI 运算性能直接相关,一个是全新一代的 Tensor Core,它加入了对 TF32(TensorFloat-32)的运算支持,这是一个先前 NVIDIA 旧架构 GPU 并不支持的运算,它能够让 GPU 在 AI 运算方面变得更加灵活、高效。
另一个是结构稀疏性加速,NVIDIA 的研发人员对 AI 计算进行了深层次的探究,通过利用 AI 运算在数学上固有的稀疏性,配合硬件优化增强 AI 运算的性能。

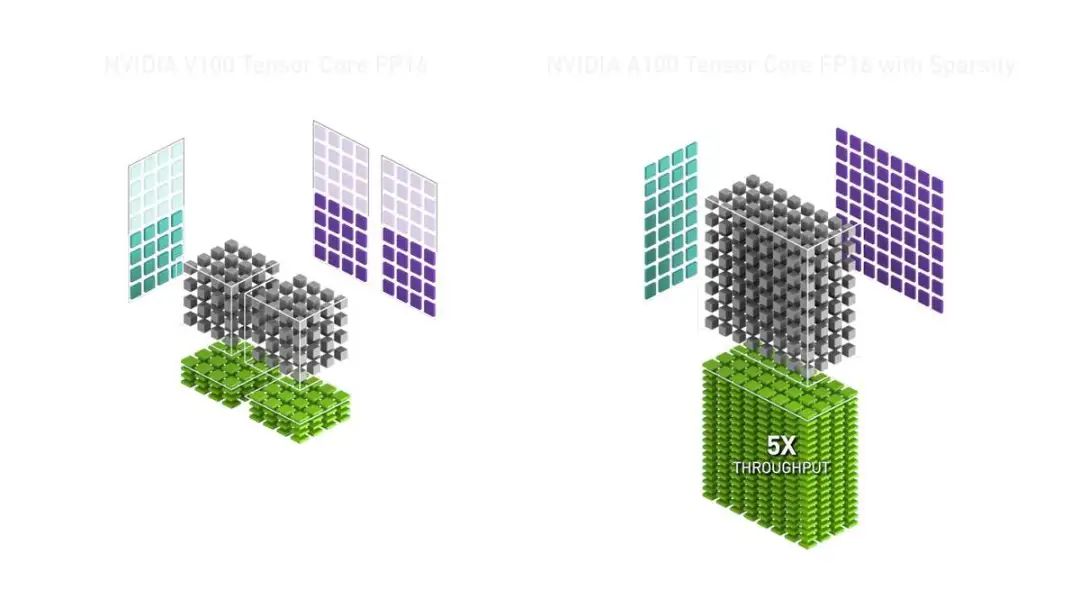
这两点结合在一起,在 AI 运算方面,A100 的综合提升是相当惊人的,总体的运算吞吐量能够提升高达 20 倍(相较于 V100 在 FP32 运算下的性能)。同样,在新的技术下,其他类型的浮点数运算性能也能够得到很明显的提升。在实际的应用上,对于 AI 模型的训练,A100 能够比 V100 快数倍。
可以看出,至少目前 NVIDIA 在 Ampere 架构上呈现出来的新特性和优势是在向 AI 运算这方面倾斜的,NVIDIA 也是希望自己能够很好地把控住用于深度学习的硬件,让 GPU 更加适合深度学习,以对抗那些专门为 AI 运算研发的 NPU 们。
在学术、科研这个领域,就目前 NVIDIA 拿出来的东西来看,他们还是很希望自己能够继续保持他们在这一领域的一个优势地位,尽量让自家的产品不被其他的产品超过。A100 总体上在 AI 运算方面是有很多侧重的,和他们在 AI 运算做的提升相比,浮点数运算性能、流处理器数量的提升只是 NVIDIA 架构升级换代里相对更常规一些的提升,算不上是亮点。
可以预见的是,未来游戏卡搭载的 Tensor Core 一定也会是全新的 Tensor Core,这意味着 NVIDIA 在游戏领域能够进一步借助显卡强大的 AI 运算性能去实现一些更多神奇的东西,比如类似于 NVIDIA 目前已经推出的 DLSS 2.0 这种技术。
之所以在消费级卡里保留 Tensor Core,一方面 NVIDIA 考虑到一些个人开发者、小型团队 / 科研机构可能预算不是那么足,没有办法像很多大型企业、大型机构一样使用 V100、A100 这样的顶级计算卡,所以他们也在游戏卡里加入了 Tensor Core,给这些有需求的消费者一个更经济的选择。
另一方面,NVIDIA 其实也对 AI 技术未来在图形领域的发展有一个非常好的预期,毕竟在深度学习火的这么长时间里,它确实给图形图像处理这一领域带来了很多新鲜、神奇的新技术,NVIDIA 也相信未来 AI 可能会在消费级领域里带来一些革命性的东西,在硬件上加入 Tensor Core 只是他们为了消费者在未来能够体验到这样的技术而提前打下的一个基础。
事实证明 NVIDIA 走的这条路是没有什么问题的,他们之前一段时间推出的 DLSS 2.0 实际上就具有一定的革命性,它非常成功地利用 AI 技术让玩家游戏的流畅度得到一个巨大的提升。
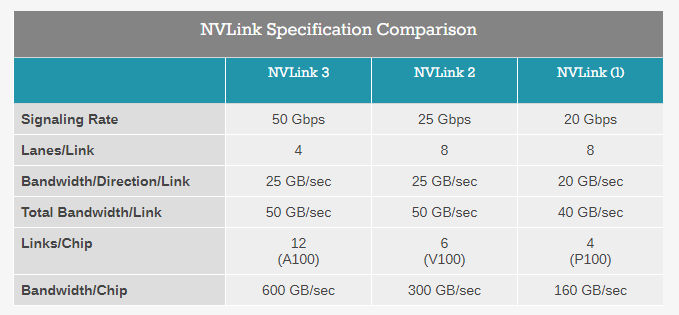
在新一代的显卡上 NVIDIA 推出了全新一代的 NVLink —— NVLink 3。这一代 NVLink 更多是在上一代 NVLink 的技术上进行了一些资源分配的调整,使得单个 Link 能够达到更高的带宽和信号率,实际上本质上它和 NVLink 2 是没有太多区别的。
不过这个 NVLink 和 Quadro、Geforce 系显卡上的 NVLink 是不太一样的,它主要被用在 DGX 这样的服务器上,而普通显卡的 NVLink 虽然和这个有相似之处,但是二者不能一概而论。
最终 NVIDIA 在 Quadro、Geforce 系显卡上做的 NVLink 在效率和带宽上也是有限的,目前我们所看到的 NVLink 3 参数在笔者个人看来没有很高的参考价值,而且对于绝大绝大多数用户来说,NVLink 也是基本上用不到的。
展望未来 NVIDIA 推出的新一代游戏卡,我们目前可以基本确定两件事情,第一是它在基础的运算性能上,得益于架构的进步和制程的进步,它相较于现有的 Turing 架构可能会有一个 20% 左右的提升,毕竟那些塞到芯片的、更大量的晶体管总要发挥一些作用。
第二是游戏卡的 Tensor Core 极大可能会随着 A100 的升级而升级,不过这个升级需要和后续 NVIDIA 推出或升级的新技术搭配才能够让普通消费者从中受益。
相较于这两点既定的提升,笔者反而更希望看到 NVIDIA 在 RT(实时光线追踪)方面做出大进步、实现大提升,因为 RT 技术不论和专业领域还是普通玩家玩游戏都是关联十分密切的,而且和传统的即时渲染相比,光线追踪毫无疑问能够呈现一个更加逼近真实,细节更加丰富、更加细腻的渲染结果,它能够给很多领域带来新的可能,最终用户得到的体验提升也是简单粗暴的。
而 AI 方面的提升更多只能惠及开发者,对于普通消费者和一些专业用户来说,只有当某个基于 AI 的、很有特色且效果强悍的新技术被研发出来,或者某个软件 / 游戏亦或是系统本身对于 AI 计算资源有一个很好的利用,我们才能够切实地得到体验的提升,相较于 RT 方面的提升,在 AI 这个方向上,我们所期待的「提升」会具有更多的偶然性。